버블 정렬
버블 정렬은 배열의 처음부터 시작해 첫 번째와 두 번째 요소를 비교하는 정렬 알고리즘이다. 첫 번째 요소가 두 번째 요소보다 크면 두 요소의 위치를 바꾼다. 이 비교 과정은 다음 쌍으로 이동하며 배열이 완전히 정렬될 때까지 반복한다. 이 과정에서 작은 값이 점점 배열의 앞쪽으로 "떠오른다"는 특징이 있다. 큰 값이나 무거운 요소가 배열의 끝으로 가라앉는 모습 때문에 이 알고리즘을 싱킹 정렬(Sinking sort)이라고 부르기도 한다.
실행 시간:
- 평균: O(N^2)
- 최악: O(N^2)
메모리:
- O(1)
구현
이 알고리즘의 평균 및 최악의 실행 시간을 고려할 때 매우 비효율적이므로 실제 구현은 보여주지 않는다. 하지만 개념을 이해하면 간단한 정렬 알고리즘의 기초를 파악하는 데 도움이 될 것이다.
버블 정렬은 매우 간단한 정렬 알고리즘이다. 배열에서 인접한 두 요소를 비교하며, 첫 번째 요소가 더 크면 두 요소의 위치를 바꾼다. 그렇지 않으면 아무 작업도 하지 않고 다음 비교로 넘어간다. 이 과정을 배열의 요소 개수 n만큼 반복한다.
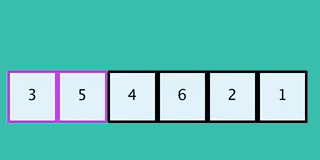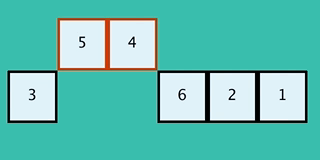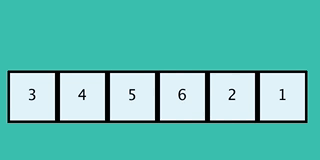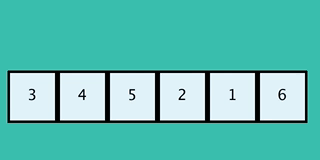
이 GIF는 일반적인 버블 정렬과는 반대 방향으로 동작하는 구현을 보여준다.
예제
배열 [5, 1, 4, 2, 8]을 버블 정렬을 사용해 가장 작은 수부터 가장 큰 수로 정렬해 보자. 각 단계에서 굵은 글씨로 표시된 요소를 비교한다. 총 세 번의 패스가 필요하다.
첫 번째 패스
[ 5 1 4 2 8 ] -> [ 1 5 4 2 8 ], 알고리즘이 처음 두 요소를 비교하고, 5 > 1이므로 교환한다.
[ 1 5 4 2 8 ] -> [ 1 4 5 2 8 ], 5 > 4이므로 교환한다.
[ 1 4 5 2 8 ] -> [ 1 4 2 5 8 ], 5 > 2이므로 교환한다.
[ 1 4 2 5 8 ] -> [ 1 4 2 5 8 ], 이 요소들은 이미 정렬된 상태(8 > 5)이므로 알고리즘은 교환하지 않는다.
두 번째 패스
[ 1 4 2 5 8 ] -> [ 1 4 2 5 8 ]
[ 1 4 2 5 8 ] -> [ 1 2 4 5 8 ], 4 > 2 이므로 교환
[ 1 2 4 5 8 ] -> [ 1 2 4 5 8 ]
[ 1 2 4 5 8 ] -> [ 1 2 4 5 8 ]
이 시점에서 배열은 이미 정렬되었지만, 알고리즘은 이를 알지 못한다. 알고리즘은 정렬이 완료되었음을 확인하기 위해 한 번의 전체 패스 동안 교환이 발생하지 않아야 한다.
세 번째 패스
[ 1 2 4 5 8 ] -> [ 1 2 4 5 8 ]
[ 1 2 4 5 8 ] -> [ 1 2 4 5 8 ]
[ 1 2 4 5 8 ] -> [ 1 2 4 5 8 ]
[ 1 2 4 5 8 ] -> [ 1 2 4 5 8 ]
네 번째와 다섯 번째 패스에서도 동일하다.
for i in 0..<array.count {
for j in 1..<array.count {
if array[j] < array[j-1] {
let tmp = array[j-1]
array[j-1] = array[j]
array[j] = tmp
}
}
}
return array최적화
버블 정렬 알고리즘은 n번째 패스에서 n번째로 큰 요소를 찾아 최종 위치에 배치한다는 점을 관찰하면 쉽게 최적화할 수 있다. 따라서 내부 루프는 n번째 실행 시 마지막 n-1개의 항목을 확인하지 않아도 된다:
for i in 0..<array.count {
for j in 1..<array.count - i {
if array[j] < array[j-1] {
let tmp = array[j-1]
array[j-1] = array[j]
array[j] = tmp
}
}
}
return array두 번째 줄에서 1..<array.count를 1..<array.count - i로 변경한 것이 유일한 수정 사항이다. 이를 통해 비교 횟수를 절반으로 줄일 수 있다.
최적화된 코드로 정렬을 수행하면 배열 [5, 1, 4, 2, 8]에 대해 다음과 같은 순서로 진행된다:
첫 번째 패스
[ 5 1 4 2 8 ] -> [ 1 5 4 2 8 ], 5 > 1이므로 교환
[ 1 5 4 2 8 ] -> [ 1 4 5 2 8 ], 5 > 4이므로 교환
[ 1 4 5 2 8 ] -> [ 1 4 2 5 8 ], 5 > 2이므로 교환
[ 1 4 2 5 8 ] -> [ 1 4 2 5 8 ], 8 > 5이므로 이미 정렬된 상태. 교환하지 않음
첫 번째 패스가 끝나면 마지막 요소가 가장 큰 값이 됨
두 번째 패스
[ 1 4 2 5 8 ] -> [ 1 4 2 5 8 ]
[ 1 4 2 5 8 ] -> [ 1 2 4 5 8 ], 4 > 2이므로 교환
[ 1 2 4 5 8 ] -> [ 1 2 4 5 8 ], 첫 번째 루프가 한 번 실행되었으므로 내부 루프는 여기서 멈추고, 5와 8을 비교하지 않음
세 번째 패스
[ 1 2 4 5 8 ] -> [ 1 2 4 5 8 ]
[ 1 2 4 5 8 ] -> [ 1 2 4 5 8 ] 다시 한 번 비교를 멈춤
네 번째 패스
[ 1 2 4 5 8 ] -> [ 1 2 4 5 8 ]
다섯 번째 패스는 존재하지 않는다.
결론
제안된 최적화를 적용해도 이 알고리즘은 여전히 매우 비효율적인 정렬 방식이다. 더 나은 대안으로는 Merge Sort를 고려할 수 있다. Merge Sort는 성능이 우수할 뿐만 아니라 구현 난이도도 비슷하다.
Swift Algorithm Club을 위해 Julio Brazil이 업데이트함